Open Gazer
Open Gazer Review
- Name of the technology: Open Gazer
- Link: http://www.inference.phy.cam.ac.uk/opengazer/
- Price: Free
- Popularity: NA
- Minimal physical requirements: The patient has to be able to move his head freely.
Detailed Description:
Opengazer is an open source application that uses an ordinary webcam to estimate the direction of your gaze. This information can then be passed to other applications. For example, used in conjunction with Dasher, opengazer allows you to write with your eyes. Opengazer aims to be a low-cost software alternative to commercial hardware-based eye trackers.
The first version of Opengazer was developed by PiotrZieliński, supported by Samsung and the Gatsby Charitable Foundation. More detail about this version can be found.
Research for Opengazer has been revived by Emli-Mari Nel, and is now supported by the European Commission in the context of the AEGIS project and the Gatsby Charitable Foundation.
The previous version of Opengazer is very sensitive to head-motion variations. To rectify this problem we are currently focussing on head tracking algorithms to correct for head pose variations before inferring the gaze positions. All the software is written in C++ and Python. An example video of one of our head tracking algorithm can be downloaded [here]. On Windows the video can be viewed with the VLC player. On Linux it is best displayed using Mplayer Movie Player.
The first version of our head tracking algorithm is an elementary one, based on the Viola-Jones face detector, that locates the largest face in the video stream (captured from a file/camera) as fast as possible, on a frame-by-frame basis. The xy-coordinates from tracking can already be used to type using Dasher. This can be done in 1D mode (e.g., from tracking just the y-coordinates), or in 2D mode. Although much better results can be expected after the release of our head-pose software, this software is already useful for fast face localisation. Our algorithm applies a simple autoregressive lowpass filter on the xy-coordinates and scale of the detection results from the Viola-Jones face detector, and also restricts the region of interest from frame to frame. The detection parameters have been determined according to our specific application (i.e., a single user working on his/her Desktop PC/laptop). The algorithm works best on 320x240 images, at a frame rate of 30 fps, and reasonable lighting conditions.
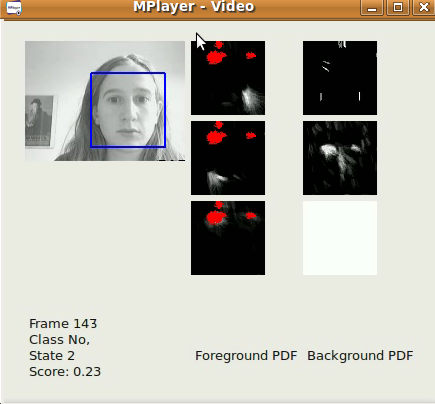
A subproject of Opengazer involves the automatic detection of facial gestures to drive a switch-based program. This program has a short learning phase (under 30 seconds) for each gesture, after which the gesture is automatically detected. Many patients (e.g., patients with cerebral palsy) have involuntary head motions that can introduce false positives during detection. We therefore also train a background model to deal with involuntary motions. All the software is written in C++ and Python and will be available for download soon. An example video of our gesture switch algorithm can be downloaded [here]. On Windows the video can be viewed with the VLC player. On Linux it is best displayed using Mplayer Movie Player. Note that this video has sound. Three gestures have been trained to generate three possible switch events: a left smile, right smile, and upwards eyebrow movement all correspond to switch events. The background model, in this case, detects blinks, sudden changes in lighting, and large head motions. The first official release will be at the end of June 2012.
The first version of Opengazer has the following workflow:
Feature point selection:
During startup the user is expected to select feature points on the face using the mouse. These points are tracked in subsequent steps in the algorithm. The first two points correspond to the corners of the eyes, which are also used in subsequent steps to extract the eye images. The user has to keep his/her head very still during the whole procedure. At this point the user should preferably save all the selected feature points.
Calibrating the system:
During this step a few red dots are displayed at various positions on the screen. Images of the eyes are extracted during the display of each dot. The eye images and their corresponding dot positions are used to train a Gaussian Process that represents the mapping between the image of an eye and the position on the screen. Note that changes in head pose often requires the system to be recalibrated.
Tracking:
After all the calibration dots are processed the Gaussian Process yields a predictive distribution, so that the expected point of eye focus on the display monitor can be estimated given a new image of the eye. If the user loads his/her selected feature points, the Viola Jones face detector is used once to determine the search region where the feature points are expected. Subsequently, optical flow is used to track each feature point. The eye images are extracted (using the first two selected corner points as reference), and the gaze is predicted using the extracted eye images and the trained Gaussian Process.