警告:このページは自動(機械)翻訳です。疑問がある場合は、元の英語のドキュメントを参照してください。ご不便をおかけして申し訳ありません。
Gazerを開く
Gazerレビューを開く
- 技術の名前: Gazerを開く
- リンク: http://www.inference.phy.cam.ac.uk/opengazer/
- 価格: 自由
- 人気: NA
- 最小限の物理的要件: 患者は頭を自由に動かせる必要があります。
詳細な説明:
Opengazerは、通常のWebカメラを使用して視線の方向を推定するオープンソースアプリケーションです。この情報は、他のアプリケーションに渡すことができます。たとえば、Dasherと組み合わせて使用すると、opengazerは目で書くことができます。 Opengazerは、市販のハードウェアベースのアイトラッカーに代わる低コストのソフトウェアを目指しています。
Opengazerの最初のバージョンはPiotrZielińskiによって開発され、SamsungとGatsby Charitable Foundationによってサポートされました。このバージョンの詳細については、こちらをご覧ください。
Opengazerの研究はEmli-Mari Nelによって復活し、現在はAEGISプロジェクトとGatsby Charitable Foundationのコンテキストで欧州委員会によってサポートされています。
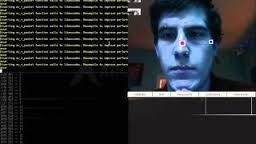
Opengazerの以前のバージョンは、頭の動きの変化に非常に敏感です。この問題を修正するために、現在、視線位置を推測する前に頭の姿勢の変化を修正するために、頭追跡アルゴリズムに焦点を合わせています。すべてのソフトウェアはC ++およびPythonで作成されています。頭部追跡アルゴリズムの1つのサンプルビデオをダウンロードできます[こちら]。 Windowsでは、VLCプレーヤーでビデオを表示できます。 Linuxでは、Mplayer Movie Playerを使用して最適に表示されます。
ヘッドトラッキングアルゴリズムの最初のバージョンは、Viola-Jones顔検出器に基づく初歩的なもので、ビデオストリーム(ファイル/カメラからキャプチャされた)で最大の顔をフレームごとにできるだけ早く特定します。フレーム単位。追跡からのxy座標は、Dasherを使用して入力するために既に使用できます。これは、1Dモード(y座標のみの追跡など)または2Dモードで実行できます。ヘッドポーズソフトウェアのリリース後、はるかに優れた結果が期待できますが、このソフトウェアはすでに顔のローカライズに役立ちます。このアルゴリズムは、Viola-Jones顔検出器からの検出結果のxy座標とスケールに単純な自己回帰ローパスフィルターを適用し、フレームごとに関心領域を制限します。検出パラメーターは、特定のアプリケーション(つまり、デスクトップPC /ラップトップで作業する1人のユーザー)に従って決定されています。このアルゴリズムは、320 x 240の画像、30 fpsのフレームレート、および適切な照明条件で最適に機能します。
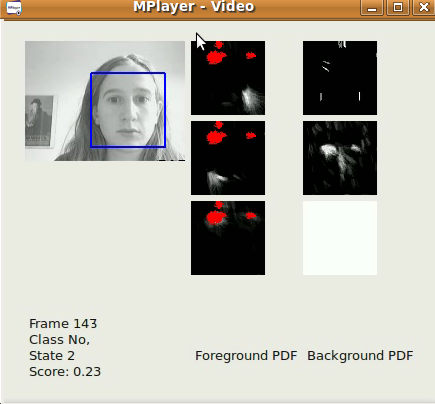
Opengazerのサブプロジェクトには、スイッチベースのプログラムを駆動するための顔のジェスチャの自動検出が含まれます。このプログラムには、ジェスチャごとに短い学習フェーズ(30秒未満)があり、その後ジェスチャが自動的に検出されます。多くの患者(たとえば、脳性麻痺の患者)は、検出中に偽陽性を引き起こす可能性のある不随意の頭の動きを持っています。そのため、不本意な動きに対処するための背景モデルも訓練します。すべてのソフトウェアはC ++およびPythonで記述されており、まもなくダウンロードできるようになります。ジェスチャスイッチアルゴリズムのサンプルビデオは[こちら]からダウンロードできます。 Windowsでは、VLCプレーヤーでビデオを表示できます。 Linuxでは、Mplayer Movie Playerを使用して最適に表示されます。このビデオには音声があることに注意してください。左スマイル、右スマイル、上向きの眉の動きの3つの切り替えイベントを生成するために、3つのジェスチャがトレーニングされています。これらはすべて、切り替えイベントに対応しています。この場合、背景モデルは、瞬き、照明の突然の変化、および大きな頭の動きを検出します。最初の公式リリースは2012年6月末です。
Opengazerの最初のバージョンには、次のワークフローがあります。
特徴点の選択:
起動時に、ユーザーはマウスを使用して顔の特徴点を選択する必要があります。これらのポイントは、アルゴリズムの後続のステップで追跡されます。最初の2点は目の角に対応します。これは、目の画像を抽出する後続の手順でも使用されます。ユーザーは、手順全体を通して頭を非常に静かに保つ必要があります。この時点で、ユーザーは選択したすべての特徴点を保存することが望ましいです。
システムの調整:
この手順の間、画面上のさまざまな位置にいくつかの赤い点が表示されます。目の画像は、各ドットの表示中に抽出されます。目の画像とそれに対応するドット位置は、目の画像と画面上の位置との間のマッピングを表すガウス過程を訓練するために使用されます。多くの場合、頭のポーズの変更にはシステムの再キャリブレーションが必要です。
追跡:
すべてのキャリブレーションドットが処理された後、Gaussianプロセスは予測分布を生成します。そのため、ディスプレイモニター上の予想されるアイフォーカスのポイントは、目の新しい画像が与えられたときに推定できます。ユーザーが選択した特徴点を読み込むと、Viola Jones顔検出器が一度使用され、特徴点が予想される検索領域が決定されます。その後、オプティカルフローを使用して各特徴点を追跡します。目画像が抽出され(最初の2つの選択されたコーナーポイントを参照として使用)、抽出された目画像と訓練されたガウス過程を使用して視線が予測されます。