تحذير: هذه الصفحة هي ترجمة آلية (آلية) ، في حالة وجود أي شكوك ، يرجى الرجوع إلى المستند الأصلي باللغة الإنجليزية. نعتذر عن أي إزعاج قد يسببه هذا الأمر.
افتح جازر
افتح جازر مراجعة
- اسم التكنولوجيا: افتح جازر
- حلقة الوصل: http://www.inference.phy.cam.ac.uk/opengazer/
- السعر: مجانا
- شعبية: NA
- الحد الأدنى من المتطلبات المادية: يجب أن يكون المريض قادرًا على تحريك رأسه بحرية.
وصف مفصل:
Opengazer هو تطبيق مفتوح المصدر يستخدم كاميرا ويب عادية لتقدير اتجاه نظراتك. يمكن بعد ذلك نقل هذه المعلومات إلى تطبيقات أخرى. على سبيل المثال ، يستخدم بالاشتراك مع Dasher ، يتيح لك opengazer الكتابة بعيونك. يهدف Opengazer إلى أن يكون بديلاً منخفض التكلفة لبرامج تتبع العين التجارية القائمة على الأجهزة.
تم تطوير الإصدار الأول من Opengazer بواسطة PiotrZieliński ، بدعم من Samsung ومؤسسة Gatsby الخيرية. يمكن العثور على مزيد من التفاصيل حول هذا الإصدار.
تم إحياء Emli-Mari Nel البحوث الخاصة بـ Opengazer ، وهي مدعومة الآن من قبل المفوضية الأوروبية في سياق مشروع AEGIS ومؤسسة Gatsby الخيرية.
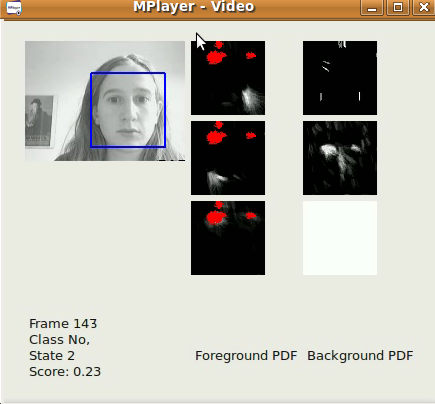
الإصدار السابق من Opengazer حساس للغاية للاختلافات الرأسية. لتصحيح هذه المشكلة ، نركز حاليًا على خوارزميات تتبع الرأس لتصحيح الاختلافات التي تطرأ على الرأس قبل استنتاج مواضع النظرة. تتم كتابة جميع البرامج في C ++ و Python. يمكن تنزيل مقطع فيديو مثالي لأحد خوارزميات تتبع الرؤوس لدينا [هنا]. على Windows ، يمكن مشاهدة الفيديو باستخدام مشغل VLC. على نظام Linux ، يتم عرضه بشكل أفضل باستخدام Mplayer Movie Player.
الإصدار الأول من خوارزمية تتبع الرؤوس لدينا هو إصدار أولي ، يستند إلى كاشف الوجه Viola-Jones ، الذي يحدد أكبر وجه في دفق الفيديو (يتم التقاطه من ملف / كاميرا) بأسرع وقت ممكن ، على إطار تلو الآخر أساس الإطار. يمكن بالفعل استخدام إحداثيات xy من التتبع للكتابة باستخدام Dasher. يمكن القيام بذلك في وضع 1D (على سبيل المثال ، من تتبع إحداثيات y فقط) ، أو في وضع 2D. على الرغم من أنه يمكن توقع نتائج أفضل بكثير بعد إصدار برنامج head-pose الخاص بنا ، إلا أن هذا البرنامج مفيد بالفعل لتوطين الوجه السريع. تطبق الخوارزمية الخاصة بنا مرشحًا بسيطًا للارتداد الذاتي للإنحدار على إحداثيات xy ومقياس لنتائج الكشف من جهاز كشف الوجه Viola-Jones ، كما يقيد المنطقة ذات الاهتمام من إطار إلى إطار. تم تحديد معلمات الكشف وفقًا لتطبيقنا المحدد (أي مستخدم واحد يعمل على جهاز الكمبيوتر المكتبي / المحمول الخاص به). تعمل الخوارزمية بشكل أفضل على صور 320 × 240 ، بمعدل إطارات يصل إلى 30 إطارًا في الثانية ، وظروف إضاءة معقولة.
يتضمن المشروع الفرعي لـ Opengazer الاكتشاف التلقائي لإيماءات الوجه لدفع برنامج قائم على التبديل. يحتوي هذا البرنامج على مرحلة تعليمية قصيرة (أقل من 30 ثانية) لكل إيماءة ، يتم بعدها اكتشاف الإيماءة تلقائيًا. كثير من المرضى (مثل مرضى الشلل الدماغي) لديهم حركات غير إرادية في الرأس يمكن أن تقدم إيجابيات كاذبة أثناء الكشف. لذلك نحن ندرب أيضًا نموذجًا أساسيًا للتعامل مع الحركات اللاإرادية. تتم كتابة جميع البرامج في C ++ و Python وستكون متاحة للتنزيل قريبًا. يمكن تنزيل فيديو مثال لخوارزمية تبديل الإيماءات [هنا]. على Windows ، يمكن مشاهدة الفيديو باستخدام مشغل VLC. على نظام Linux ، يتم عرضه بشكل أفضل باستخدام Mplayer Movie Player. لاحظ أن هذا الفيديو يحتوي على صوت. تم تدريب ثلاث إيماءات لتوليد ثلاثة أحداث تبديل محتملة: الابتسامة اليسرى ، والابتسامة اليمنى ، وحاجب الحاجبين لأعلى تتوافق جميعها مع أحداث التبديل. يكشف نموذج الخلفية ، في هذه الحالة ، عن الوميض والتغيرات المفاجئة في الإضاءة وحركات الرأس الكبيرة. سيكون الإصدار الرسمي الأول في نهاية يونيو 2012.
يحتوي الإصدار الأول من Opengazer على سير العمل التالي:
اختيار نقطة الميزة:
أثناء بدء التشغيل ، يتوقع من المستخدم تحديد نقاط المعالم على الوجه باستخدام الماوس. يتم تعقب هذه النقاط في الخطوات اللاحقة في الخوارزمية. تتوافق النقطتان الأوليان مع زوايا العينين ، والتي تُستخدم أيضًا في الخطوات اللاحقة لاستخراج صور العين. يجب على المستخدم الحفاظ على رأسه ثابتًا للغاية خلال الإجراء بأكمله. في هذه المرحلة ، يفضل أن يحفظ المستخدم جميع نقاط الميزات المحددة.
معايرة النظام:
خلال هذه الخطوة ، يتم عرض بضع نقاط حمراء في مواقع مختلفة على الشاشة. يتم استخراج الصور من العينين خلال عرض كل نقطة. يتم استخدام صور العين ومواضعها المقابلة لتدريب عملية Gaussian التي تمثل التعيين بين صورة العين والموضع على الشاشة. لاحظ أن التغييرات التي تطرأ على الرأس تتطلب غالبًا إعادة ضبط النظام.
تعقب:
بعد معالجة جميع نقاط المعايرة ، تعطي عملية Gaussian عملية توزيع تنبؤية ، بحيث يمكن تقدير نقطة تركيز العين المتوقعة على شاشة العرض في ضوء صورة جديدة للعين. إذا قام المستخدم بتحميل نقاط الميزة الخاصة به / لها ، فسيتم استخدام كاشف الوجه Viola Jones مرة واحدة لتحديد منطقة البحث التي يتوقع أن تكون نقاط الميزة فيها. بعد ذلك ، يتم استخدام التدفق البصري لتتبع كل نقطة ميزة. يتم استخراج صور العين (باستخدام أول نقطتين أساسيتين تم تحديدهما كمرجع) ، ويتم التنبؤ بالنظرة باستخدام صور العين المستخرجة وعملية Gaussian المدربة.